Joakim Melin
Björeman // Melin // Åhs, avsnitt 447: Kanalisera min inre skåning ⚓
Ett trevligt lagom långt avsnitt där vi doppar tårna i vår sommar så här långt.
Unifi Protect G4 Instant ⚓
Efter att ha använt Homekit secure video och Eufy:s Solo Indoorcam C24 i snart tre år började jag fundera. Kostnaden för lagring i iCloud hade dubblerats under denna tid och eftersom Apple i sin visdom1 krävde när jag skaffade detta att man har den största lagringsplanen som erbjuds via iCloud+, två terabyte, om du har fler än en kamera kopplad till Homekit secure video så det var bara att vackert slanta upp varje månad för en hel lagringsutrymme som jag i praktiken inte behövde eller använde.
Jag började titta på gratis kameraprogramvaror som exempelvis Zoneminder och installerade till och med upp det hela men det visade sig snart att mina kameror från Eufy inte ville prata ONVIF eller något annat protokoll så de gick i praktiken inte att ansluta till Zoneminder.
Efter mitt tidigare köp av en Unifi Dream Router 7 så började jag fundera på om jag inte kunde dra ner min kostnad för iCloud+ ganska dramatiskt och samtidigt bli mindre beroende av en molntjänst för mitt övervakningsbehov2.
En snabbt titt på kamerautbudet från Ubiquiti gav vid handen att de inte var så vansinnigt dyra att köpa så jag slog till på en Unifi Protect G4 Instant för drygt 1200 kronor. För denna relativt låga prislapp får man en hel del trevligheter för pengarna. Kameran är väderskyddad och går att montera utomhus. Strömmatningen sker via USC-C och kameralinsen har en upplösning på 2K (fyra megapixel) och en uppdateringsfrekvens på 30 bilder per sekund. “Mörkerseendet” är på upp till sex meters avstånd och den har både högtalare och mikrofon samt något Ubiquiti kallar “AI detections”, det vill säga, den ska klara av att fatta om den ser en människa, en hund eller en bil och sedan kunna agera utifrån det som att exempelvis sortera upp bilder den fångat.
Det som inte finns är en möjlighet att driva denna kamera med en ethernetanslutning (Power over ethernet, eller PoE) vilket helt klart är ett avbräck för många, i synnerhet med tanke på att det är enklare att dra en rejält skärmad ethernetkabel utomhus för att strömsätta kameran och samtidigt överföra data från den.
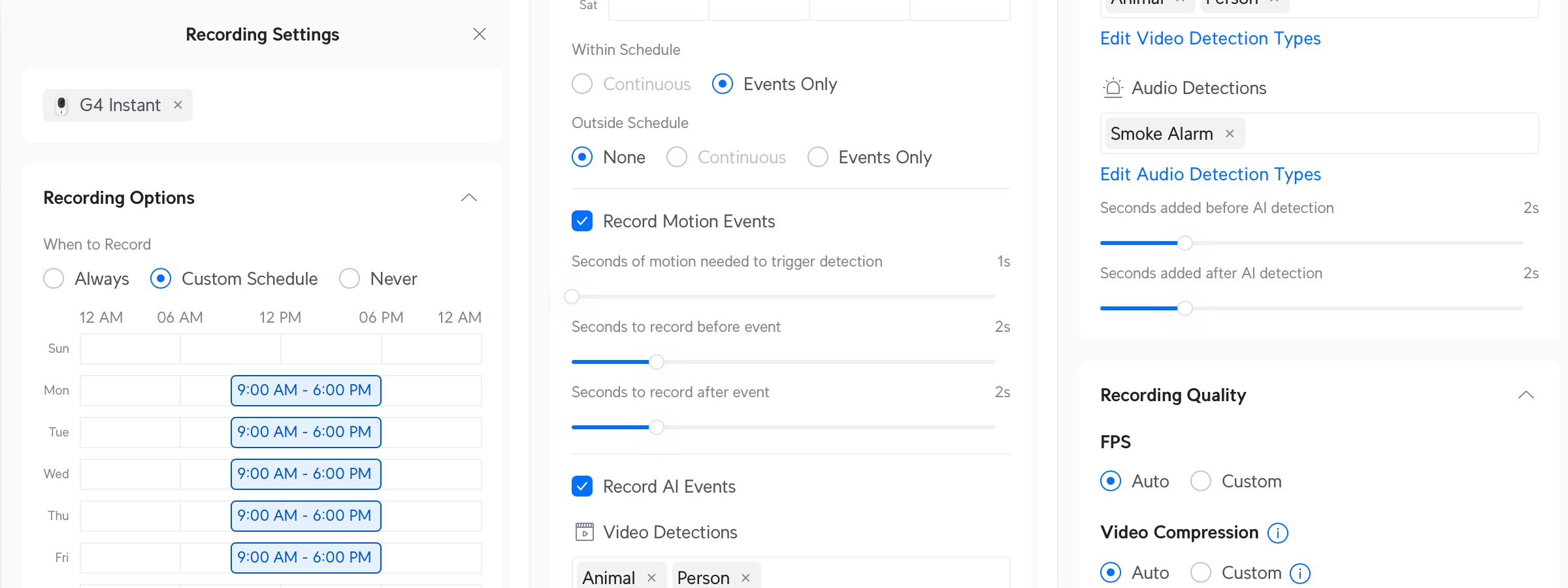
Installationen av denna kamera är en aning “yxig”. Man börjar med att lägga till Protect-applikationen i Dream Router, vilket tar sin lilla tid. Därefter kan man montera upp och koppla in kameran, vilket jag gjorde med den synnerligen effektiva dubbelhäftade tejp som Ubiquiti så vänligt skickade med.
Dream Routern hittar sedan kameran och man kan lägga till den på samma sätt som en extra wifi-basstation. Detta tar också en stund. Därefter ska kameran uppgraderas till sin senaste programvara, vilket tar en stund. Kort sagt - det yxiga är kanske inte så mycket i själva utförandet utan snarare att det tar en väldig tid att få igång saker och ting. Efter att kameran är inlagd i Protect-applikationen kan man börja konfigurera saker och ting, som exempelvis schemaläggningen vilket också är ett kapitel för sig och i mitt tycke lite väl komplicerat:
{kind=link}
En funktion som jag såg fram emot att använda är vad som kallas geofencing, det vill säga att Protect-applikationen ska känna av att jag, och min iPhone, närmar mig mitt hem och därmed slå av kameran. Det fungerar av någon anledning inte alls, och att konfigurera detta var också rätt bökigt i att det inte går att göra från Unifi- eller Protect-applikationerna i min iPhone utan det måste göras med webbgränssnittet.
Vidare är det ju inte bara jag som bor i den här lägenheten men det finns inget sätt att tala om det för Protect-applikationen bortom att installera samma applikation på mina barns telefoner och logga in dem och det är något jag inte vill göra.
Här har Homekit och Homekit secure video en fördel i att alla som är en del av “hemmet” i Home-applikationen också kan tillåtas automatiskt slå av eller på kameraövervakningen genom att komma hem eller gå ut ur hemmet. Sen att det inte alltid fungerade till hundra procent är väl en annan pilsner. Kanske går detta att lösa om jag gräver vidare i Ubiquitis plattform och inställningar som, i ärlighetens namn, är rätt rörigt uppbyggda. Jag får be att återkomma i ärendet.
Notifieringarna är faktiskt riktigt bra, och riktigt snabba. Ovan ser du hur en notifiering till min iPhone ser ut.
Så här ser det ut på Apple Watch.
Vill man ta upp en händelse i Protect-applikationen på sin iPhone så kan man enkelt göra det och titta på inspelade händelser:
Vill man tjyvkika hur läget är hemma så går det givetvis bra, även när det är kolsvart där kameran är placerad:
Notera att det här också anges hur mycket lagringskapacitet som finns för inspelade händelser. Denna lagringskapacitet begränsas av storleken på SD-kortet som är installerat i min Dream Router 7 och till skillnad från förra generationens Dream Router inkluderar Ubiquiti vänligt nog ett 64 gigabyte stort SD-kort i köpet av Dream Router 7.
Ska man summera den här lösningen så fungerar den trots allt riktigt bra. När man väl tagit den stora smällen och köpt en Dream Router 7 eller annan “bas” för sin framtida Unifi-installation så är dessa kameror och andra tillbehör inte så fasligt dyra och Ubiquiti har numera i princip allt under solen som man kan vilja koppla in så precis som min gode vän Christian en gång sa så är det inte svårt att halka in i Unifi-träsket och bli kvar där - deras grejer är verkligen välbyggda. Härnäst är jag lite sugen på en dörrklocka att integrera i mitt system, och en UniFi Protect G4 Doorbell ser verkligen inte otrevlig ut.
Uppgradering av hemlabbet ⚓
Ibland får man en sån där tanke som man inte riktigt kan släppa. Som ett myggbett som fortsätter klia långt efter att det försvunnit. Det är uppgraderingsdjävulen som slagit till, och den tenderar att sticka upp sitt fula tryne lite då och då för oss som kör en eller flera servrar i ett hemlabb, kanske i synnerhet när man liksom landat sitt hemlabb och allt bara fungerar lite för bra.
Givetvis är detta ett läge att göra av med ohemuliga summor på något du egentligen inte behöver, som exempelvis en snabbare nätverkswitch.
Givetvis är detta vad jag gjorde.
Minus det där med ohemuliga summor.
Låt mig förklara. Jag ville uppgradera mitt hemmalabb till 2,5 gigabit-nätverk. Min OPNsense-brandvägg har 2,5 gigabit ethernet-portar. Min Unifi Dream Router 7 har 2,5 gigabit ethernet-portar. Borde inte min Proxmox-server och min Truenas Scale-server också ha det?
Svaret är givetvis ett rungande ja!
Problemet är bara att jag ju börjat ge mig in i Unifi-träsket. Och alla som börjat knalla in där vet att man vill ju bara ha en Unifi-pryl till. Jag började därför titta på 2,5 gigabit ethernet-switchar (eller 2,5GbE-switchar som det också kallas) från Ubiquitis Unifi-familj och för en enkel fem-portars 2,5GbE-switch från Ubiquiti av modell UniFi USW Flex Mini 2.5G får man punga ut i storleksordningen 800 kronor. Inte så farligt, kan man tycka men om den har fem portar så ryker en till att ansluta min andra befintliga switch och resterande fyra räcker inte till, så jag måste köpa två och vips är vi uppe i 1600 kronor.
Den modell jag egentligen hade behövt, en UniFi Flex 2.5G med åtta 2,5GbE-portar portar plus en 10 gigabit SFP+-port (den sistnämnda är perfekt för att ansluta till min befintliga switch, en Mikrotik CSS326-24G-2S+RM, som även den råkar ha 10 gigabit SFP+) dansar in på runt 2300 kronor inklusive moms.
I det här läget är det lätt att blunda och klicka på köp-knappen i en webshop och leva på nudlar ett par veckor, men jag var ståndaktig och kanaliserade min inre smålänning och tänkte att det måste finnas något billigare?
Dags att köpa en switch
Svaret är givetvis ja - svaret är Ali Express!
Ni som läst min blogg ett tag vet ju att jag brukar handla diverse galenskaper därifrån ibland, och ibland blir man bränd och ibland så kan man ha tur och köpa bra grejer. Denna gång hände både- och.
Jag började med att gräva efter en switch. Jag ville inte ha en switch som stödde PoE, den behövde inte vara managerbar och den behövde inte ha VLAN-stöd. Däremot behövde den ha minst fem 2,5GbE-portar och minst en 10GbE+-port.
Den här switchen verkade vara lagom shady för min smak. Den är helt enkelt skitkorkad, men prislappen som då låg på strax under 400 kronor med frakt, vilket var lite för lågt för att ignorera. Hisource 2.5G None-POE Network Switch 5 8 Port Ethernet Switch with 2*10G SFP+ for IP Camera/NVR heter den. Bli inte lurad - det står “Network Switch 5 8 port” och betyder att du antingen köper en switch med fem portar eller en med åtta. Choose wisely.
Denna switch ska klara av att skyffla upp til 65Gbps och ska tydligen kunna hantera “blixtnedslag” på upp till “fyra kilovolt”.
Hur som helst, den är skitkorkad. Så jag beställde den och fäste den under skrivbordet, kopplade ihop den via SFP+ med min Mikrotik-switch och det fungerar så fint så. Dokumentationen för denna switch är givetvis ett skämt, och när man precis lyckats sluta skratta häcken av sig så ser man en liten omkopplare på switchens framsida med texten “S V” och under “V” står det “VLAN”. Ingenstans i dokumentationen nämns vad detta betyder, vad syftet är eller hur, om möjligt detta ska användas, bara att omkopplaren finns där. Jag lämnde den i läge “S” och det fungerar bra.
Nätverkskort då?
Switchens köp får alltså anses vara en framgång. Nätverkskorten från AliExpress kan man väl säga var det inte.
Jag tänkte att jag inte ska snåla med nätverkskorten. Jag ska inte köpa något med ett chipset från Broadcom1 utan Intel skulle det vara. Så jag slog till och köpte två stycken Intel I225-V3 Game PCIE Card 2500Mbps Gigabit Network Card 10 100 1000Mbps RJ45 Wired Computer PCIe 2.5G Network Adapter LAN2 för 129 kronor styck. De skulle bygga på Intels i225-krets och enligt beskrivningen fungera med ESXI 7.0, OpenWRT, Unraid, “PVE”, Windows 10 och 11 samt “Linux”.
Spänningen var därför olidlig när korten till slut leverades och jag började med att installera ett i min Truenas Scale-server. Det gick inget vidare - servern vägrade ens boota med kortet installerat. Så jag testade det andra kortet jag köpt och resultatet var det samma. Jag installerade ett av korten i min speldator med Windows 10 och startade upp den. Windows hittade kortet utan problem och identifierade kortet som ett Intel-kort och att hastigheten var 2,5GbE. Det fungerade bra…. i ungefär 30 sekunder. Sedan tyckte Windows 10 att kortet inte längre hade någon länk. Datorn skulle ändå installeras om med Linuxdistributionen Fedora och nu hittades kortet och det verkar faktiskt också fungera felfritt, iallafall under de timmar jag kört datorn med det installerat och aktivt.
Jag vågade inte ens testa att stoppa in ett sånt här kort i min Proxmox-server varvid jag gjorde lite mer research, bad min inre smålänning att sluta skrika på mig och köpte två stycken TP-Link TX201 som till skillnad från AliExpress-korten faktiskt har en historik av att fungera med de operativsystem jag ville skulle använda dessa kort.
De är nu båda installerade i mina respektive servrar och kanske går det inte så mycket snabbare egentligen, jag maxar garanterat inte ut bandbredden som jag nu har i mitt hemlabb men det känns iallafall lite rappare och det där imaginära myggbettet har slutat klia nu… åtminstone för en stund.
Unifi Dream Router 7 ⚓
Min teknikstack har börjat landa riktigt fint nu och utöver min lilla servermiljö underskrivbordet har jag en Mac mini m4 ovanpå samma bord som bara tuffar på. En begagnad Macbok Air M1 har gjort datorparken sällskap, och vill du köpa en är det dags att börja fundera på det nu för de har rasat i pris. Det är i sin tur rätt obegripligt egentligen för de är fortfarnade galet snabba och bra datorer, trots att det närmar sig fem år sedan de lanserades.
Tillsammans med en iPhone 16 pro och en Apple Watch series 10 har jag äntligen roterat och uppgraderat i princip hela min teknikpark. Det kan låta slösaktigt och kanske pompöst men när man så gott som alltid hankat sig fram på de lite billigare produkterna så är det skönt att kunna drämma plånboken i bordet (även om jag ofta av nära och kära beskrivs som allt mellan “frugal” och “dumsnål”) och skaffa det man verkligen vill ha. De grejer jag har nu borde jag överleva 3-4 år med utan problem.
När jag säger “i princip” så var det två “saker” som återstod: wi-fi-nätet i min lägenhet och mina övervakningskameror. Jag har testat ett antal olika grejer genom åren, allt från enklare och billigare produkter från TP-Link (nu senast AX1800 i en mesh-konfiguration) till en Dream Router som verkligen var trevlig men också lite för långsam och inte helt tyst. Den Dream Routern går för övrigt till historien som en av de få teknikprodukter jag köpt, använt ett år och sedan sålt för mer pengar än jag köpte den för.
En sak som Dream Routern var väldigt, väldigt bra på var att erbjuda wi-fi-täckning i min lägenhet. Anledningen till att jag valde att bygga mitt wi-fi-nätverk i en Mesh-konfiguration är att lägenheten består av betongväggar och gipsväggar. Det gör att en lite klenare lösning inte när ut till hela lägenhetens alla rum varför en mesh-konfiguration är att föredra. Mesh i sin tur är dock inte perfekt - man tappar i bandbredd med varje “hopp” från huvudarbetsstationen och AX1800 hade också ett annat problem: när den fick lite för mycket att göra så tenderade den ibland att bara sluta fungera några sekunder. Troligen var det buffertminnet i den som blev fullt och den orkade helt enkelt inte med att skyffla data i den takt som den borde och bestämde sig för att “spola” ur buffertminnet. Wi-fi 6 skulle den också klara och visst, det gick rätt fort men i närheten av gigabithastigheter kom jag då aldrig.
Det jag gillade med min gamla Dream Router, utöver designen som, verkligen är oerhört snygg, är den inbyggda programvaran. Ubiquiti har verkligen börjat leverera när det gäller gränssnittsdesign de senaste åren. Funktionsmässigt var det också en riktigt grym maskin, om än med en lite för klen processor och därmed också inte överdrivet bra prestanda över WAN-porten när man aktiverat paketinspektion och annat trevligt. Mer om det senare. Det jag inte gillade var skärmen:
Om jag skulle tvingas hitta något annat att klaga på så är det detta: varför är ‘skärmen’ i Dream Router så oerhört löjligt liten? De hade kunnat göra den aningen större och därmed också mer användbar.
Kamerorna då? Mina två övervakningskameror från Eufy har väl fungerat okej, men verkligen inte mer än så. Ibland “ballar de ur” en stund och bara slutar fungera, tappar kontakten med omvärlden en liten stund, och så vidare. Med tanke på att de var ruggigt billiga så ska man väl kanske inte förvänta sig mer än så heller. Kamerorna går heller inte att ansluta till något annat än Eufys egna molntjänst eller till iCloud via Homekit och då jag är väldans sugen på att minska ner mitt molnanvändande och köra merparten av mina tjänster hemma landade jag i att dessa kameror också måste bytas.
Tankegångarna landade snart på Ubiquiti:s lösningar. Jag kom ihåg att deras Dream Router hade en inbyggd mjukvara för att hantera Ubiquitis egna kameramodeller och jag har hört bra saker om deras kameror. Tankengången där efter var inte lång till att jag landade på att titta på Ubiquitis produktutbud anno 2025 och svaret fanns rakt framför ögonen på mig.
Så jag köpte en Dream Router 7. Prislappen var en tusenlapp mer än vad jag betalade för min första Dream Router, men ser man vad man får i paketet så ser man var pengarna tar vägen. Skärmens storlek är för övrigt oförändrad men man kan inte få allt helt enkelt. På framsidan finns det således i princip ingenting som skvallrar om att detta är en ny modell. Baksidan, däremot, har en hel del att berätta.
Som tidigare sitter här fyra ethernet-anslutningar, men de har uppgraderats till 2,5Gbit/s jämfört med den förra modellens 1Gbit/s. Värt att notera är att Dream Router 7 precis som sin föregångare erbjuder PoE men till skillnad från sin föregångare kan den som mest mata ut 15,4 watt, till skillnad från 40 watt i den äldre modellen. Strömförbrukningen är detta till trots högre i den nyare modellen, drygt 13 watt, där den äldre drog drygt 9,5 watt. Båda värdena är utan någon PoE-belastning.
Utöver det finns det också en port under de fyra ethernet-portarna, och det är en SFP+-port. Just det - du kan här peta in en SFP+-modul och få 10Gbit/s via fiberkabel eller via ethernet (om kablaget tillåter det). Den lilla blå WAN-symbolen visar också att du faktiskt kan ha två WAN-anslutningar till denna router, vilket är glädjande för en person som undertecknad som en gång i timmen la många timmar på att försöka hacka en USG att inte bara acceptera två WAN-anslutningar utan att också kunna hantera NAT och port forward och sådant för båda. Det gick inget vidare, för övrigt.
Under SFP+-porten sitter SD-kort-platsen och till skillnad från den tidigare Dream Router-modellen har Ubiquiti haft vänligheten att inkludera ett SD-kort på 64GB när man köper en Dream Router 7.
Dream Routerns akilleshäl var i mitt tycke hastigheten över WAN-porten. Att sitta med 1Gbit/s internetanslutning och i praktiken få ut hälften var verkligen inte roligt. Det var också en högst bidragande orsak till att jag sålde den.
Med Dream Router 7 är saker och ting lite annorlunda. Precis som med min första Dream Router så tycker Dream Router 7 att den kan prata jättefort med Internet, men efter att man aktiverade allehanda brandväggsfunktioner (IDS och IPS) så fick Dream Router snart problem. Skulle Dream Router 7 ha samma problem?
| Hastighet ned, Mbps | Hastighet upp, Mbps | |
|---|---|---|
| Dream Router | 564 | 625 |
| Dream Router 7 | 937 | 915 |
Tester gjorda med Speedtest.net
Förklaringen till detta är, givetvis, att Dream Router 7 har mer muskler under skalet än sin föregångare. Den första Dream Router-modellen drevs av en två-kärnors Cortex A53-processor på 1,35Ghz med två gigabyte interminne. Den nya Dream Router 7 har i princip samma processor men nu begåvad med fyra processorkärnor som tickar på i 1,5Ghz och till det tre gigabyte internminne. Genomströmningshastigheten med IDS och IPS påslaget har också ökat från 1Gbps till 2,3Gps (detta är givetvis teoretiska siffror men det ger en fingervisning om att Dream Router 7 har mer muskler att ta till vid behov).
Tittar man på wi-fi-kompetens i Dream Router 7 så är den också kraftigt förbättrad:
| Dream Router 7 | Dream Router | |
|---|---|---|
| 6Ghz | Upp till 5,7Gpbs | Stöds ej |
| 5Ghz | Upp till 4.3Gbps | Upp to 2.4Gbps |
| 2,4Ghz | Upp till 688 Mbps | Upp till 576Mbps |
Med min iPhone 16 pro över 6Ghz-bandet får jag drygt 850Mbps i ned- och uppladdningshastighet, vilket för mig känns helt galet bra. Jag kanske har levt i forntiden med lite enklare produkter och att börja närmare sig samma hastigheter som trådbunden gigabit ethernet-anslutning är fascinerande.
Integration med Unifi-kameran får jag återkomma till då den ännu inte levererats men om den fungerar lika bra som denna router gör så levererar den en betydligt stabilare och säkrare lösning än vad jag lämnar bakom mig. Det ska också noteras att Dream Router 7 kan hantera “över” 30 Unifi-enheter (kameror, accesspunkter, och så vidare) vlket kan jämföras med “över” 20 Unifi-enheter för den äldre Dream Router-modellen. Antalet samtidigare användare har fördubblats i Dream Router 7, från över 150 till över 300 dito.
Min OPNsense-router då. kanske du frågar? Numera har jag två publika IP-adresser hem så den ena IP-adressen kör jag mina publika servrar och sådant över, och den IP-adressen hanterar OPNsense, medan den andra IP-adressen hanterar klienter och detta hanterar Dream Router 7.
Teknikstack 2025 ⚓
En gång i tiden bodde jag i ett hus. Med en källare. I den källaren hade jag ett rack, med nätverksutrustning, brandväggar, servrar, ett fibre channel-anslutet SAN, UPS-enhet, och så vidare. Det var trevligt, och fint. Men det var snart fem år sedan och efter det har jag på olika sätt testat att köra en liten tystare och enklare driftmiljö hemma för diverse experiment. Ett tag körde jag det hela på tre stycken små HP Microserver, därefter körde jag ett kluster med fyra Raspberry Pi 4 med 8GB RAM vardera och efter det hyrde jag en server i Finland ett år.
Det jag hela tiden har velat göra är att försöka minimera elförbrukning och värmeutveckling, hitta sätt att minimera hur mycket tid jag måste lägga på att underhålla en hemmabaserad driftplattform och, givetvis, göra om saker ibland mest för att det faktiskt kan vara roligt och lärorikt.
Borta är som bekant de dagar då man kunde skaffa sig en eller ett par Mac mini och ett operativsystem från Apple som faktiskt innehöll serverfunktioner, så numera är det öppen källkod som gäller. Det roliga där är ju att det finns mycket att välja på när man vill göra det riktigt komplicerat för sig, vilket i sig inte heller är särskilt tråkigt.
Jag tänkte att det kunde vara kul att nörda ned sig på allvar. Att bygga en komplex, kraftfull, skalbar och ändå ekonomiskt försvarbar hemmadrift av en bunt publika webbsajter och tjänster. Utöver denna webbsajt kör jag också en Mastodoninstans, webbsajten för podden jag är med i varje vecka, ett filarkiv för gamla datorer, en Matrix-server, och så vidare Jag gör allt detta på en enkel PC, med fyra två-terabyte SSD-hårddiskar (uppsatta i en RAID-Z1 via zfs), en åtta-kärnorsprocessor av modell Ryzen 5 2400G, 64 gigabyte internminne, Proxmox för att virtualisera det hela och ett rätt stort chassi att ha det hela i. Det stora chassit medger stora, långsamma, fläktar vilket håller nere ljudvolymen.
Tidigare körde jag ett kluster med tre HP Prodesk-datorer av modell mindre vilket var trevligt, men de klarade endast 32 gigabyte internminne vardera och kunde inte hantera snabbare nätverkskort än 1 gigabit per sekund. Så nu har jag det du ser på bilden ovan under skrivbordet. Den stora fyrkanten till höger är servern som skickade dig den här webbsidan, längt bak in mot väggen är min TrueNAS-server och till vänster om den min speldator som fortfarande fungerar så fint så, även om den inte används så ofta.
Vad har jag byggt då?
Jag funderade länge på vad jag skulle bygga den här gången. Jag tänkte att jag skulle replikera en del av den setup jag körde för sex-sju år sedan vilket fungerade bra. Dock ville jag göra vissa justeringar och ändra på saker jag inte var helt nöjd med då. Jag ville fortfarande basera mitt hemmalabb på Proxmox. Utöver det ville jag använda Haproxy, som är en programvara jag kan relativt väl. Nginx som webbserver känns alltid rätt och varför inte blanda Linux med FreeBSD? Det senare uppför sig numera riktigt bra under Proxmox (mycket tack vare att FreeBSD numera har en qemu-guest-agent som fungerar och också fungerar utmärkt med enheter som hanteras av virtio) varför det fick bli så.
Jag gillar FreeBSD mer än jag gillar Linux. Pakethanteringen är enklare och mer logisk, man slipper systemd och det är inte voodoo varje gång man vill göra ändringar i systemet.
Ett exempel: ta en titt på hur du sätter en statisk IP-adress i FreeBSD:
I filen /etc/rc.conf sätter man följande rader:
ifconfig_vtnet0=“inet 10.0.2.243 netmask 255.255.255.0”
defaultrouter=“10.0.2.1”
Här är samma manöver fast från Ubuntu Server 24.04lts:
Redigera filen /etc/netplan/00-installer-config.yaml(just det - en YAML-fil!) och lägg in följande info:
network:
ethernets:
ens18:
addresses:
- 10.0.2.28/24
nameservers:
addresses:
- 10.0.2.10
search:
- joacim.net
routes:
- to: default
via: 10.0.2.1
version: 2
Ett annat exempel? Vill jag exempelvis starta demonen för ntp-klienten vid boot så lägger jag in följande i /etc/rc.conf:
ntpd_enable=“YES”
Vill jag göra det på en Linuxdistribution med systemd?
systemctl start ntpd && systemctl enable ntpd
Detta är vansinne. En enklare Unix är så mycket roligare att arbeta med än en överkomplicerad LInux, och samtidigt är FreeBSD minst lika kraftfullt som Linux är. Så det så. (och jodå - jag vet att det finns Linuxdistributioner utan systemd men jag gillar FreeBSD bättre ändå. Detta är sannolikt den myrstack jag kommer dö relativt ensam på men låt gå för det - en man måste ha principer.)
Hur som helst - åter till bygget. En systemskiss över det hela ser ut ungefär här:
Trafikflödet till mitt webbkluster, som är ämnet för denna artikel, går som följer: Från Internet går trafiken till min brandvägg. Därefter går trafiken vidare till min reverse proxy, som körs med HaProxy som i skrivande stund körs på Rocky Linux 8. Där termineras certifikat (från Let’s Encrypt) och sedan fördelas den inkommande webbtrafiken ut beroende på var den skall (Mastodon, Matrix, webbsidor, och så vidare). Trafiken går därefter i klartext till tre backend-servrar som körs på FreeBSD 14, Nginx och PHP-FPM.
Allt statiskt content serveras från en NFS-server som körs på Rocky Linux 8, och alla databaser hanteras av en central server för detta som körs på Rocky Linux 8 och MariaDB.
Eftersom jag också hanterar sajter som körs med PHP, exempelvis Wordpress, krävs det att sessionsdatat för olika sajter delas i en central punkt vilket jag sköter med Memcached som körs på samma server som Haproxy och som sedan lagts in i /usr/local/etc/php.ini på de tre webbnoderna som körs med FreeBSD:
session.save_handler = memcached
session.save_path = “10.0.2.37:11211”
Webbnoderna har också en bunt PHP-moduler installerade som php-fpm sedan använder sig av. Dessa äro:
bcmath
Core
ctype
curl
date
dom
exif
fileinfo
filter
gd
gmp
hash
iconv
imagick
intl
json
libxml
mbstring
memcached
mysqli
mysqlnd
openssl
pcre
PDO
pdo_mysql
random
Reflection
session
SPL
standard
xml
zip
Optimeringar
Jag har lagt en hel del tid på att optimera denna plattform. Processorn har ett antal år på nacken och är inte den snabbaste, det ska erkännas, men den hänger med bra och håller sig relativt sval och drar dessutom väldigt lite el.
Till att börja med så har jag justerat parametrarna för hur jag monterar de olika ytorna för exempelvis logghantering eller content i /etc/fstab:
nfs:/nfsserver /web nfs rw nfsvers=3,auto,nofail,noatime,nolock,intr,tcp,rsize=131072,wsize=131072,actimeo=1800 0 0
NFS-servern har också fått sig en omgång. I /etc/sysctl.conf har jag lagt in följande rader för att få upp prestanda på filsystemet:
vm.vfs_cache_pressure=50
vm.swappiness=10
vm.dirty_ratio=20
vm.dirty_background_ratio=10
vm.dirty_expire_centisecs=4000
vm.dirty_writeback_centisecs=500
I filen /etc/sysctl.d/02-netIO.conf på NFS-servern har jag lagt in följande rader för att öka hastigheten på nätverksstacken:
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.core.rmem_default = 16777216
net.core.wmem_default = 16777216
net.ipv4.tcp_rmem = 4096 87380 16777216
net.ipv4.tcp_wmem = 4096 87380 16777216
net.ipv4.tcp_mem = 1638400 1638400 1638400
Summering
Det finns mycket mer att berätta än vad jag orkar göra här just nu. Kanske skriver jag en separat artikel som förklarar ACL:erna i Haproxy, vilka hade förändrats ganska radikalt sedan jag höll på med detta sist, eller så kanske jag pratar vidare om cachelösningar vilket jag håller på gräver ganska djupt i just nu.

© 2000 - 2025 Joakim Melin.
Prenumerera på bloggen via Mastodon.
